목적
- 네이버 쇼핑의 '쇼핑몰리뷰'의 평점과 텍스트 크롤링
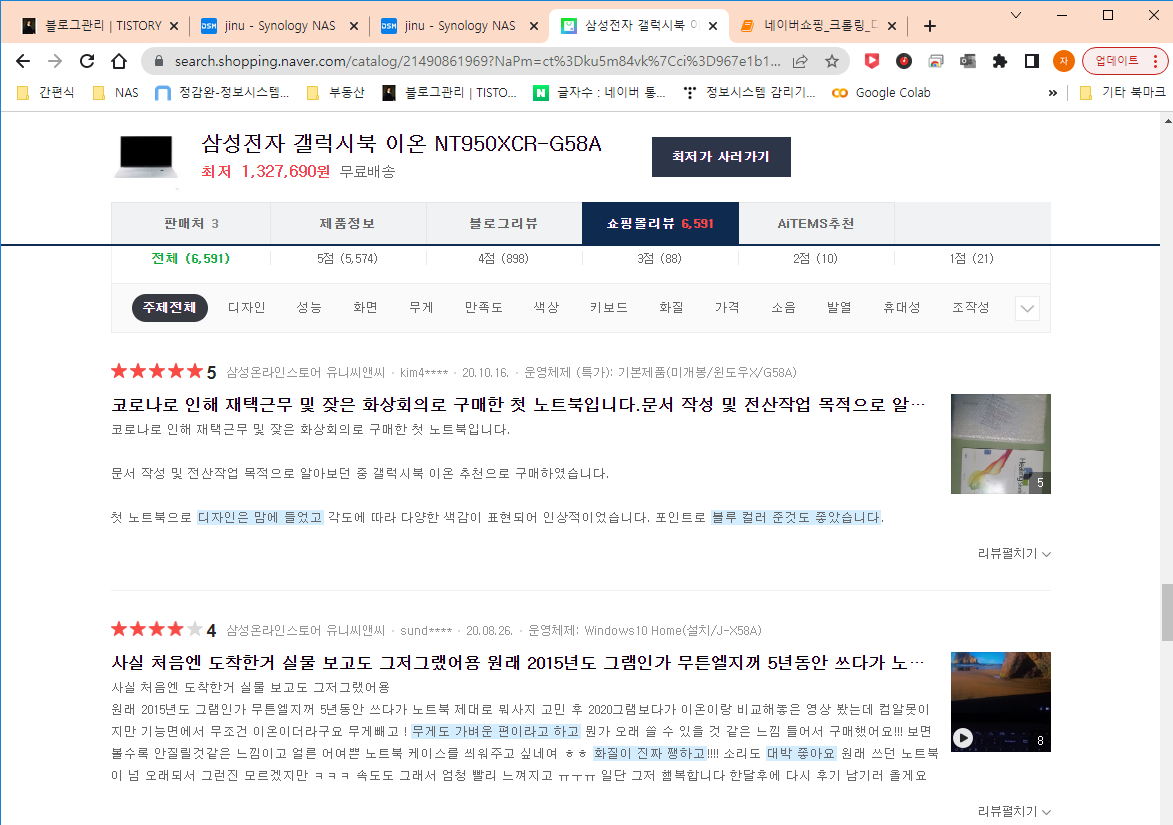
1. 필요사항 Import
- 잡플래닛은 로그인을 해야 리뷰가 보이는 사이트임
# step1.프로젝트에 필요한 패키지 불러오기
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
import pandas as pd
import requests
import re
import numpy as np
from selenium.webdriver.common.keys import Keys
2. 크롬드라이버 설정 및 로그인 정보전달
header = {'User-Agent': ''}
d = webdriver.Chrome('C:/Users/XXXXXXXXX/Downloads/chromedriver.exe') # webdriver = chrome
shoppingmall_review="/html/body/div/div/div[2]/div[2]/div[2]/div[3]/div[2]/div/div[2]/ul/li[4]/a/strong"
#함수 선언
def add_dataframe(dit,reviews,stars,cnt): #데이터 프레임에 저장
#데이터 프레임생성
df1=pd.DataFrame(columns=['크롤링구분','리뷰','평점'])
n=1
if (cnt>0):
for i in range(0,cnt-1):
df1.loc[n]=[dit[i],reviews[i],stars[i]] #해당 행에 저장
i+=1
n+=1
else:
df1.loc[n]=['null','null','null']
n+=1
return df1
3. 크롤링 대상 물품을 선정하고 URL로 정리 후 크롤링진행[Main]
**df2에 해당하는 데이터
- 실제 수집URL을 회사별로 관리하고 아래 for문에서 해당 df2를 순회하며 크롤링진행
- 파일로 담아놓아도 되고 DB Table형태로 관리해도 됨(개인적으로 Table형태를 선호함)

df1 = pd.DataFrame(columns=['크롤링구분','평점','리뷰'])
df4 = pd.DataFrame(columns=['크롤링구분','평점','리뷰'])
for dit,ns_address in zip(df2['크롤링구분'],df2['수집URL']):
#print(name_, category_ ,ns_address, "\n")
d.implicitly_wait(3)
d.get(ns_address)
req = requests.get(ns_address,verify=False)
html = req.text
soup = BeautifulSoup(html, "html.parser")
sleep(2)
element=d.find_element_by_xpath(shoppingmall_review)
d.execute_script("arguments[0].click();", element)
sleep(2)
# 리뷰 가져오기
reviews=[]
stars=[]
total_list=[]
cnt=1 #리뷰index
page=1
while True:
j=1
sleep(2)
while True: #한페이지에 20개의 리뷰, 마지막 리뷰에서 error발생
try:
star=d.find_element_by_xpath('/html/body/div/div/div[2]/div[2]/div[2]/div[3]/div[6]/ul/li[1]/div[1]/span[1]').text
star = star.replace("평점","")
review=d.find_element_by_xpath('/html/body/div/div/div[2]/div[2]/div[2]/div[3]/div[6]/ul/li['+str(j)+']/div[2]/div[1]/p').text
#reviews.append(review)
total_list.append((dit,star,review))
if j%2==0: #화면에 2개씩 보이도록 스크롤
ELEMENT = d.find_element_by_xpath('/html/body/div/div/div[2]/div[2]/div[2]/div[3]/div[6]/ul/li['+str(j)+']/div[2]/div[1]/p')
d.execute_script("arguments[0].scrollIntoView(true);", ELEMENT)
j+=1
cnt+=1
except:
break
sleep(2)
if page<11:#page10까지 적용
try: #리뷰의 마지막 페이지에서 error발생
page +=1
next_page=d.find_element_by_xpath('/html/body/div/div/div[2]/div[2]/div[2]/div[3]/div[6]/div[3]/a['+str(page)+']').click()
except:
break
else :
try: #page11부터
page+=1
if page%10==0:
next_page=d.find_element_by_xpath('/html/body/div/div/div[2]/div[2]/div[2]/div[3]/div[6]/div[3]/a[11]').click()
elif page%10==1:
next_page=d.find_element_by_xpath('/html/body/div/div/div[2]/div[2]/div[2]/div[3]/div[6]/div[3]/a[12]').click()
else :
next_page=d.find_element_by_xpath('/html/body/div/div/div[2]/div[2]/div[2]/div[3]/div[6]/div[3]/a['+str(page%10+1)+']').click()
except:
break
df4 = pd.DataFrame(total_list, columns=['크롤링구분','평점','리뷰'])
#df4=add_dataframe(dit,reviews,stars,cnt)
4. Data Frame 출력결과

2023.02.01 - [IT/Python] - [Web크롤링] 감정분석을 위한 네이버영화 코멘트/평점 Python 크롤링
[Web크롤링] 감정분석을 위한 네이버영화 코멘트/평점 Python 크롤링
목적 - 감정분석을 위해 네이버 영화평점을 크롤링 하는 파이썬 프로그램작성 - 무작위의 네이버 영화 평점별 리뷰 데이터 크롤링 https://movie.naver.com/movie/point/af/list.naver? 평점 : 네이버 영화 네티
comemann.tistory.com
2023.02.01 - [IT/Python] - [Web크롤링] 감정분석을 위한 잡플레닛 코멘트/평점 Python 크롤링
[Web크롤링] 감정분석을 위한 잡플레닛 코멘트/평점 Python 크롤링
목적 - 잡플래닛의 기업리뷰정보를 크롤링 1. 필요사항 Import 및 잡플래닛 ID와 PW기입 - 잡플래닛은 로그인을 해야 리뷰가 보이는 사이트임 # step1.프로젝트에 필요한 패키지 불러오기 from bs4 import
comemann.tistory.com
2023.02.02 - [IT/Python] - [Web크롤링] 감정분석을 위한 네이버 쇼핑 코멘트/평점 Python 크롤링
[Web크롤링] 감정분석을 위한 네이버 쇼핑 코멘트/평점 Python 크롤링
목적 - 네이버 쇼핑의 '쇼핑몰리뷰'의 평점과 텍스트 크롤링 1. 필요사항 Import - 잡플래닛은 로그인을 해야 리뷰가 보이는 사이트임 # step1.프로젝트에 필요한 패키지 불러오기 from bs4 import Beautiful
comemann.tistory.com
'IT > Python' 카테고리의 다른 글
| [국토부실거래가] 아파트 분양권 크롤링 API Python 개발 (0) | 2023.02.06 |
|---|---|
| [Web크롤링] 감정분석을 위한 잡플레닛 코멘트/평점 Python 크롤링 (0) | 2023.02.01 |
| [Web크롤링] 감정분석을 위한 네이버영화 코멘트/평점 Python 크롤링 (0) | 2023.02.01 |
| [OpenDart-1] Python으로 Dart기업정보 DataFrame으로 저장하기 (0) | 2023.01.30 |
| [Python] 으로 mariaDB(Synology DB) 연결 및 SQL결과를 Dataframe으로 저장 (0) | 2023.01.27 |