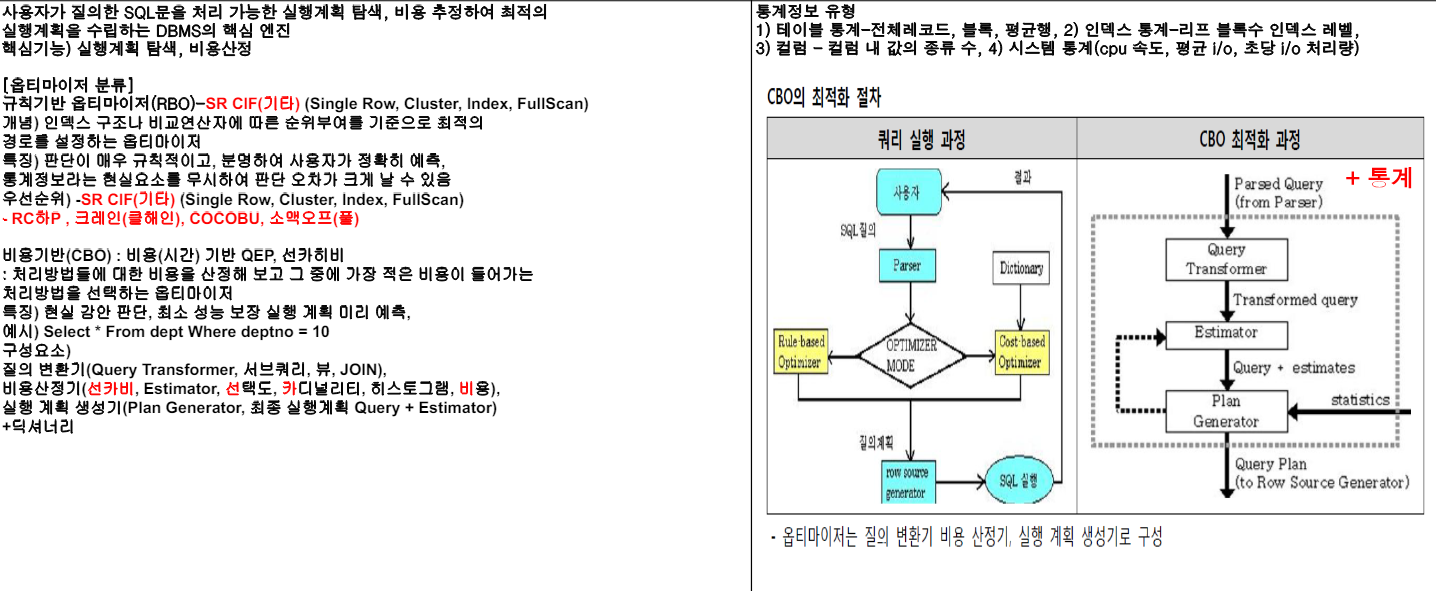
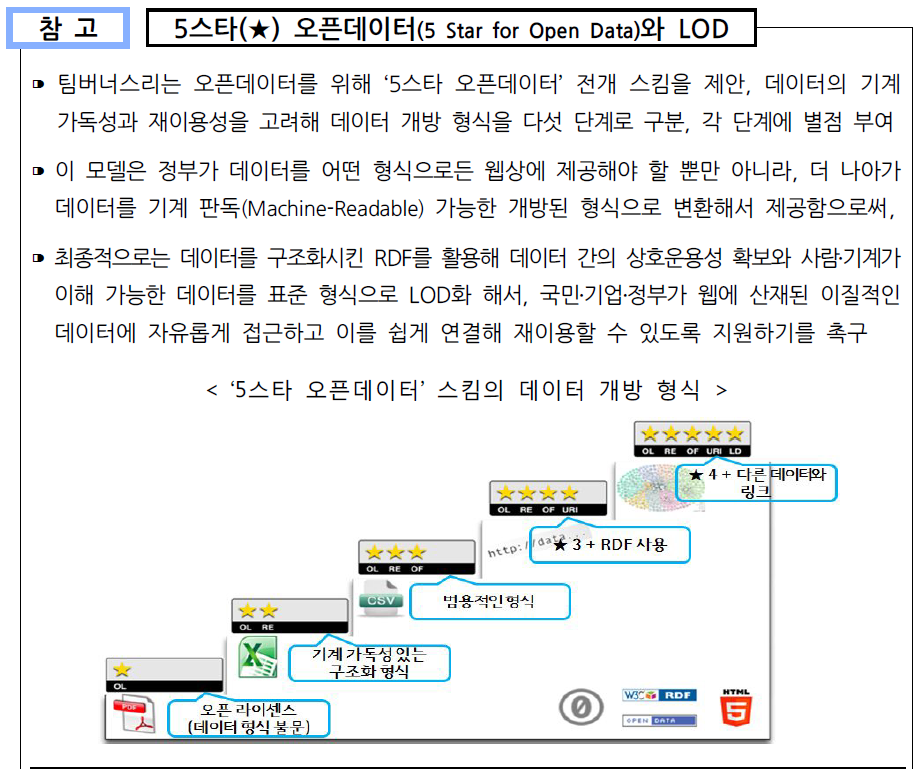
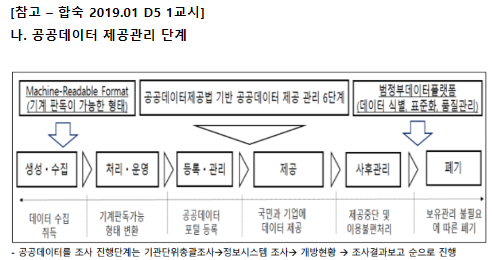
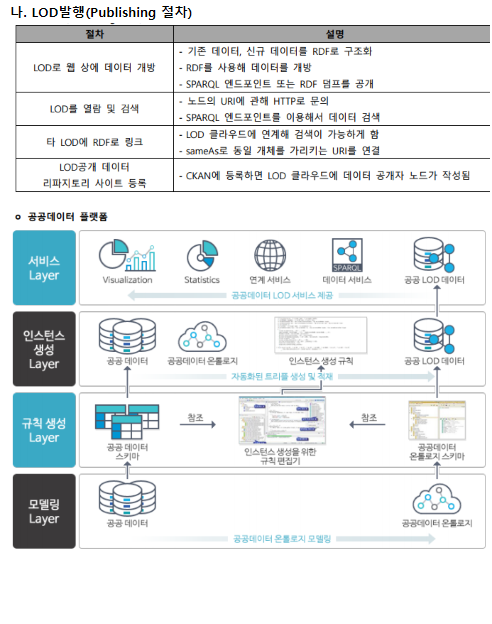
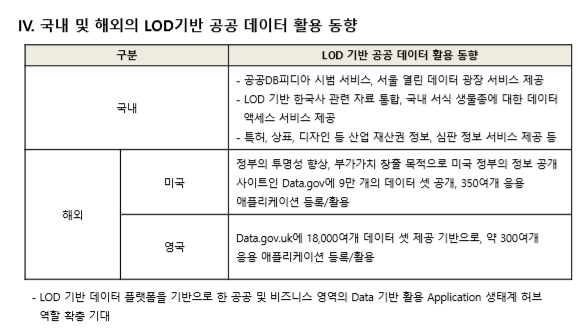
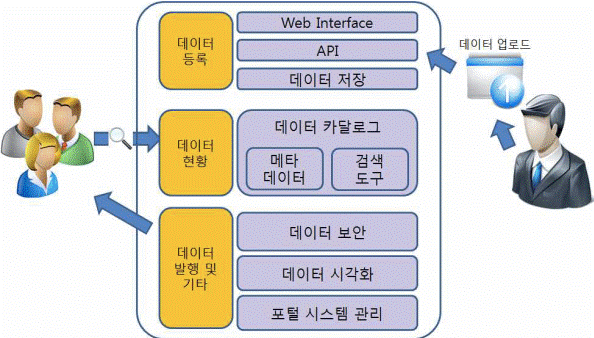
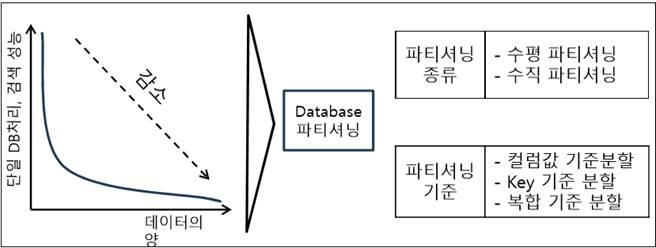
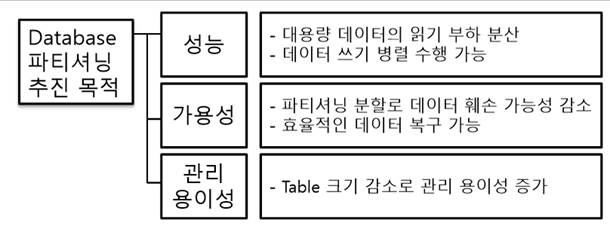
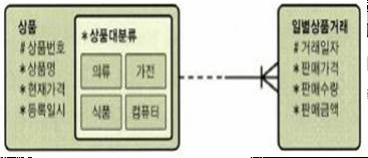
[정의] 물리적으로다른 DB에샤드라는개별파티션으로수평분할방식으로분산저장하고조회하는방법 [장점] 성능개선, 신뢰성개선, 위치추상화, 대량DB처리 [분할방법] Vertical Partitioning, Range based Partitioning, Key or Hash Based Partitioning, Directory Based Partitioning
샤드 수범키디
토픽 이름 (중)
샤딩(Sharding) / Shard
분류
DB > Data 관리 및 운영 > 샤딩(Sharding) / Shard
키워드(암기)
샤드, 라우팅프로세스, 수평분할, 분산저장
암기법(해당경우)
기출문제
번호
문제
회차
1
대용량 데이터 처리를 위한 Sharding에 대하여 설명하시오
102.관리.1.4
2
데이터베이스의 전체 시스템 부하 증가시에도 서비스의 품질을 유지시키는 기능이 바로 확장성(Scalability)이다. 확장성에관한다음 질문에 대하여 설명하시오. 가. Scale-out, Scale-up 비교 나. Horizontal scale-out, Vertical scale-out 비교 다. Sharding, Query-off loading 비교
2017.01.관리.2.3
3
데이터베이스에서 성능 향상을 위한 샤딩(Sharding), 파티셔닝(Partitioning) 기법과가용성을위한리플리케이션 Replication)과쿼리오프로딩(Query offloading)기법에 대해 설명하시오.
2018.11.관리.3.6
I. 대용량데이터처리를 위한 데이터베이스 파티셔닝 기술, Sharding의개념
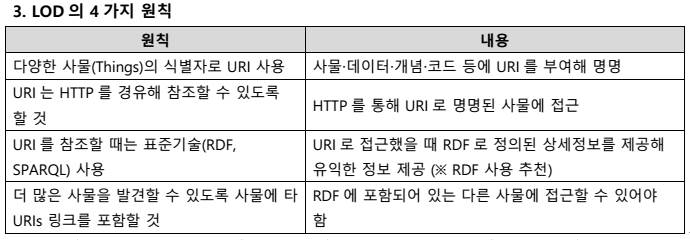
가. Sharding의정의
- DBMS 레벨에서데이터를나누는 것이 아니고 물리적으로 다른 데이터베이스에 데이터를 샤드(Shard)라고부르는각각의개별파티션으로 수평 분할 방식으로 분산 저장하고 조회하는 방법
나. Sharding의장점
장점
설명
성능 개선
큰 데이터를 압축, 개별 테이블은 각 샤드에서 더 빠른 작업을 지원
신뢰성 개선
한 샤드가 실패하더라도 다른 샤드는 데이터 서비스를 제공
위치 추상화
애플리케이션 서버에서 어떤 데이터가 어떤 데이터베이스에 위치한지 알 필요가 없음
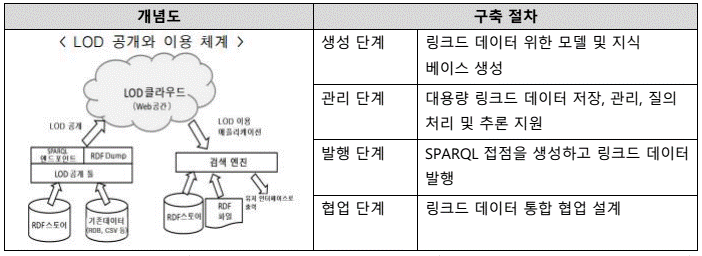
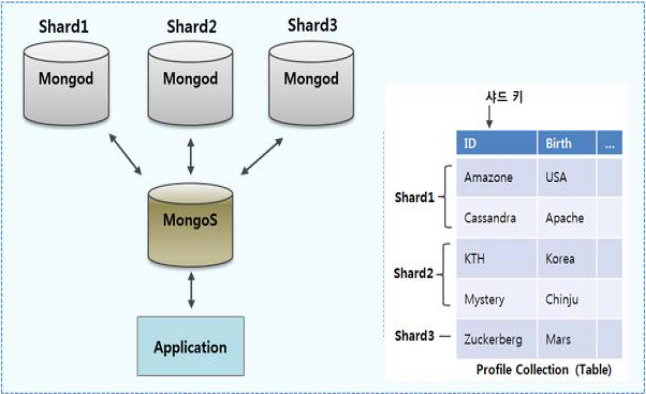
다. Sharding의개념도(몽고DB 사례)
- 샤드 키로 설정된 칼럼의 범위를 기반으로 각각의 값에 맞는 샤드에 저장 - 어플리케이션 레이어에서는 MongoS라는라우팅프로세스만연결하므로 Shard의구조에대해서는알필요도없고, 구조변경에따른수정도필요없음
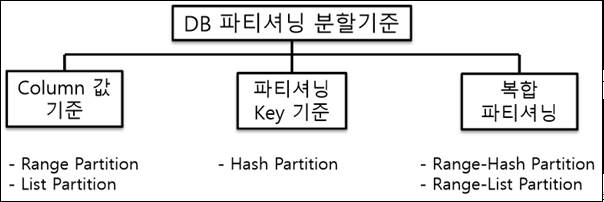
II. Sharding의데이터베이스분할 방법과 샤딩 적용시 가이드라인
Sharding의데이터베이스분할방법
방법
설명
사례/특징
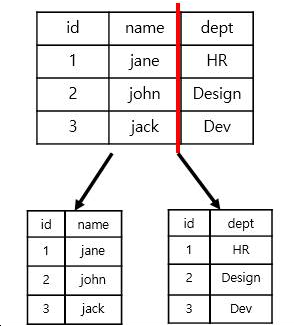
Vertical Partitioning
-테이블 별로 서버를 분할하는 방식 -구현 간단. 전체시스템에큰변화필요없음. 각서버데이터 거대해지면 추가 샤딩 필요
-사용자 프로필정보용 서버, 사용자친구리스트용서버, 사용자가 만든 콘텐츠용 서버 등으로 분할하는 방식
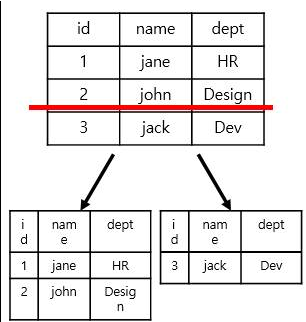
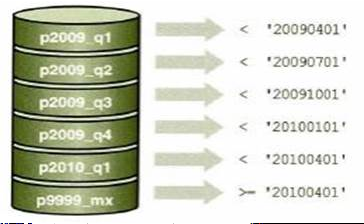
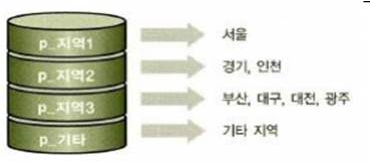
Range based Partitioning
-하나의 feature나 table이점점거대해지는경우서버를분리하는 방식 -데이터를 분할하는 방법이 예측 가능해야 함
-사용자가 많은 경우 사용자의 지역정보를 이용해서 user 별로서버를분리하거나, 일정데이터라면연도별로분리, 거래정보라면우편번호를이용하는 방식
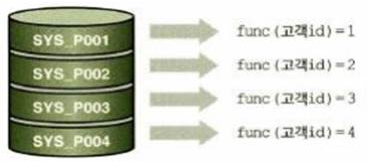
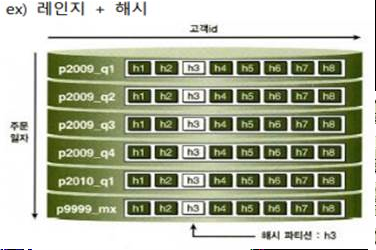
Key or Hash Based Partitioning
-엔티티를 해쉬 함수에 넣어서 나오는 값을 이용해서 서버를 정하는 방식 -해쉬 결과 데이터가 균등하게 분포되도록 해쉬함수를 정하는 게 중요
-예) 사용자ID가숫자일경우나머지연산을이용하는방법
Directory Based Partitioning
-파티셔닝 메커니즘을 제공하는 추상화된 서비스를 생성
-샤드키를 look-up 할수있으면되므로, 구현은 DB와캐쉬를적절히조합해서만들수있음
샤딩 적용 시 가이드라인
구분
가이드라인
주요 내용
DB 설계 가이드라인
데이터 재분배
서비스 정지 없이 scale-up 할수있어야함
조인
Sharding-DB 간에 조인이 불가능 하기에 처음부터 역정규화도 고려해야 함
파티션
샤드 해쉬 함수 설계가 중요
데이터는 작게
Table의 단위를 가능한 작게 만들어야 함
응용 설계 가이드라인
트랜잭션
Global Transaction을사용하면 shard DB간의트랜잭션도 가능
Global Unique Key
DBMS 에서 제공하는 auto-increment를사용하면 key가 중복될 수 있기 때문에, 어플리케이션레벨에서 GUID를 생성해야 함
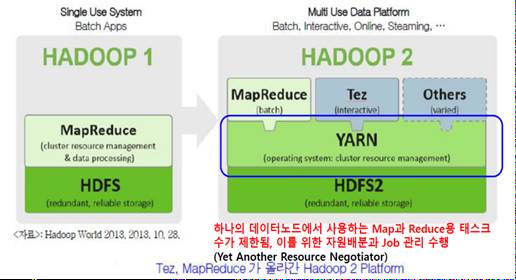
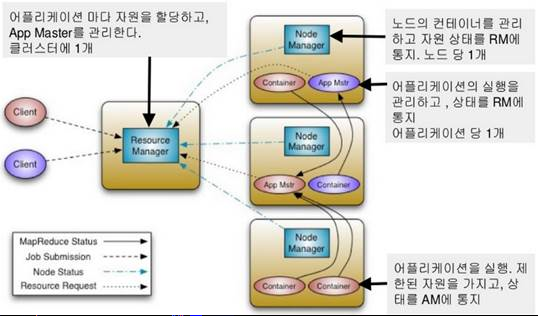
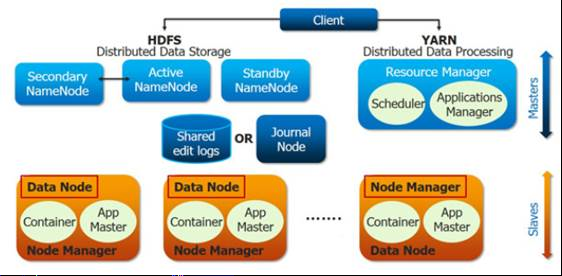
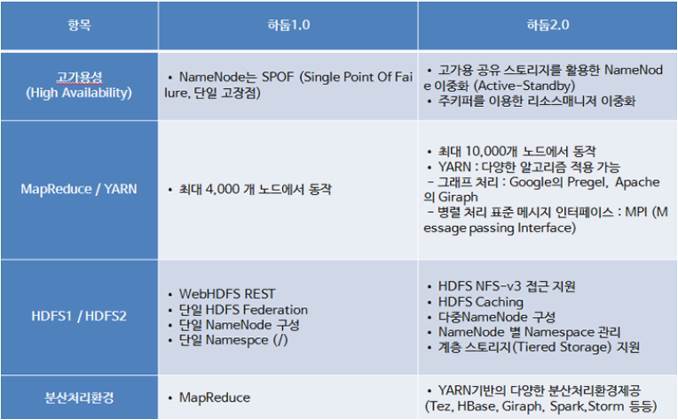
* YARN을도입하여병렬처리구조를변경 - 클러스터 관리 : 리소스매니저, 노드매니저 - 작업관리 : 애플리케이션마스터, 컨테이너 * MR 외 Spark, Hive, Pig 등다른분산처리모델도수행가능 * 클러스터당 1만개 이상의 노드 등록 가능 * 작업처리를컨테이너(container) 단위로처리
하둡 3.0
* 이레이져코딩(Erasure Coding) 도입 - 기존의블록 복제(Replication)를대체하는방식으로 HDFS 사용량 감소 * YARN 타임라인서비스 v2 도입 - 기존타임라인 서비스보다 많은 정보를 확인 가능 * 스크립트재작성및이해하기쉬운형태로수정 - 오래된스크립트를 재작성하여 버그 수정 * JAVA8 지원 * 네이티브코드최적화 * 고가용성을위해 2개 이상의 네임노드 지원 - 하나만추가할 수 있었던 스탠바이 노드를 여러개 지원가능 스탠바이 노드 * Ozone 추가 - 오브젝트 저장소 추가 global ResourceManager (RM) and per-application ApplicationMaster (AM).
[참고] YARN기반실행
Stom on YARN, 호튼웍스, Spark on YARN, Apache Giraph on YARN, HOYA(Hbase on YARN), 호튼웍스