| HDFS | 다수노드로구성된클러스터이용해, 대용량데이터집합을처리하는응용프로그램에적합한분산파일시스템 - 특징 : Fault-Tolerant, Data Block, Replication, Rack Awareness - 구성요소 : Master/Slave/Name Node/Data Node - 운영구조 : Replication, TCP/IP, Name Space |
| 토픽이름 | HDFS |
| 분류 | DB > Big Data > HDFS |
| 키워드(암기) | 대용량 데이터 저장을 위한 범용 클러스터 시스템, NameNode, DataNode, Replication, 데이터 입력 및 조회 절차 |
| 암기법(해당경우) |
[기출문제]
| 번호 | 문제 | 회차 |
| 1 | 하둡 분산파일시스템(HDFS: Hadoop Distributed File System)의 특징 및 구조에 대하여 설명하고, 구성요소인 네임노드, 데이터 노드의 역할에 대하여 설명하시오 | 111.응용.2 |
| 2 | 빅데이터 분산처리시스템인 하둡 MapReduce의 한계점을 중심으로 Apache Spark와 Apache Storm을 비교하여 설명하시오 | 105.관리.2 |
| 3 | 빅데이터 분석 도구인 R의 역사와 주요 기능 3가지에 대해 설명하시오. | 104.관리.4 |
| 4 | 맵리듀스(MapReduce) | 102.응용.1 |
| 5 | 하둡분산 파일시스템(Hadoop Distributed File System)의 구조에 대하여 설명하시오. | 101.관리.1 |
| 6 | 빅데이터 핵심기술을 오픈소스와 클라우드 측면에서 설명하고, 표준화 기구들의 동향을 설명하시오 | 101.관리.2 |
| 7 | 아파치 하둡(Apache Hadoop)의 구조와 작동 개요를 맵리듀스 엔진(MapReduce engine)중심으로 설명하시오. | 99.관리.3 |
| 8 | 빅데이터(Big Data) 처리 분석 기술인 하둡(Hadoop)에 대하여 설명하시오. | 96.응용.1 |
| 9 | 하둡2.0 에 대하여 설명하시오 | 2015.01_관리_1교시 |
| 10 | 빅데이터를 원활히 처리하기 위한 하둡기반의 병렬처리 엔진인 Pig에 대해서 다음 물음에 답하시오. 가. 개념과 특징에 대해 설명하시오. 나. 아키텍처와 구성요소에 대해 설명하시오. 다. 데이터 타입과 실행 유형에 대해 설명하시오. |
2014.12_응용_4교시 |
| 11 | 최근 빅데이터를 이용한 시스템들이 여러 분야에서 활발히 사용되고 있다. 현재 하둡을 중심으로 빅데이터를 처리/저장하였으나 실시간 빅데이터 분석의 요구가 높아짐에 따라 빅데이터를 분석할 수 있는 새로운 분산시스템들이 제시되었다. 이에 따라 다음 내용을 설명하시오 가. 하둡 기술의 현황 및 한계 나. 스파크 구조 및 특징 다. 스톰 구조 및 특징 라. 빅데이터 분산시스템 비교 및 분석 |
2014.11_관리_4교시 |
| 12 | 보안장비에서 발생하는 로그를 ESM(Enterprise Security Management) 기반으로 통합적으로 분석하였으나, 폭발적인 로그 데이터 증가와 ESM 자체의 처리 능력에 한계가 있다. Hadoop Ecosystem의 오픈소스 기술들을 사용하여 보안로그 분석을 위한 빅데이터 플랫폼을 설계하시오. | 2014.10_관리_3교시 |
| 13 | 하둡2.0(Hadoop 2.0)에 대하여 설명하시오. | 2014.01_관리_1교시z |
| 14 | Big data를 효과적으로 분석하기 위한 아키텍처로 Hadoop을 활용하는 사례가 늘어나고 있다. 그와 관련하여 Hadoop 아키텍처, MapReduce 및 HDFS에 대해서 설명하시오. | 2013.04_관리_3교시 |
| 15 | HDFS(Hadoop Distributed File System)의 개념과 동작원리를 설명하시오. | 2013.01_관리_1교시 |
| 16 | HDFS(Hadoop Distributed File System)에 대해 설명하시오 | 2011.12_응용_1교시 |
| 17 | Hadoop의 특징, 시스템 구조 및 네크워크 구조에 대해 설명하고, MapReduce의 처리방식에 대해 기술하시오. | 2011.10_응용_4교시 |
Ⅰ. Hadoop의 핵심 분산 파일 저장기술 HDFS의 개념
가. HDFS(Hadoop Distributed File System)의 정의
- 저비용의 수백, 수천 노드로 구성된 클러스터를 이용, 기가 또는 테라 바이트의 대용량 데이터 집합을 처리하는 응용 프로그램에 적합하도록 설계한 분산 파일 시스템
나. HDFS의 기술적 특징
| 특징 | 설명 |
| 높은 내고장성 (fault-tolerant) |
- H/W, N/W 부품 오류에도 정상적 운영을 보장 - 디스크I/O장애에도 Replication기법등을 통해 높은 가용성 제공 |
| 엄청난 처리량 (클러스터) | - 최대 4000개 DN, 분산 Read/Write, MapReduce |
| 빅 데이터 처리 | - 대용량 데이터 처리를 위한 경제성, 유연성, 확장성 제공 - 64M 블럭 각각의 처리 가능 |
| 파일Streaming접근 | - 순차적인 처리 특성, 이식성이 뛰어남, 고가 스토리지 불필요 |
| TCO 절감 | - Linux 및 저가형 서버구성에도 신뢰성 있는 파일시스템 제공 |
| 효율적인 분산파일 시스템 |
- 메타데이터 활용을 통해 SAN과 같은 별도 장비없이 구현가능 - NAS 문제점인 연결 노드 많을수록 성능 저하 문제점 극복 |
Ⅱ. HDFS의 구성도와 구성요소 동작 절차
가. HDFS의 구성도

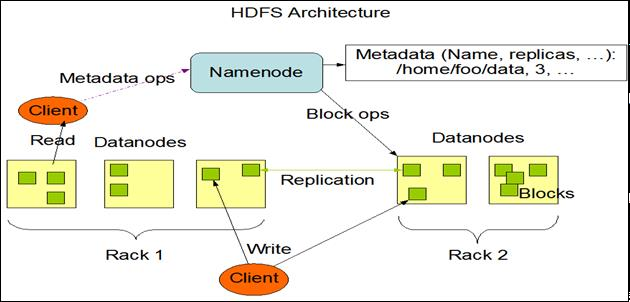
- HDFS의 구조는 크게 네임토느(Name Node)와 데이터노드(Data Node)로 나뉘며, 데이터 노드에는 실제 물리적인 데이터가 저장되고 64MB 또는 128MB 블록 사이즈로 관리되며, 모두 3개 이상의 복제본이 각 노드에 복사 및 저장되며 만일 문제가 발생되면 복제본으로 대체되 서비스가 중단되지 않는 이점이 있음.
장애상황은 항상 발생한다는 가정하에 설계됨.
나. HDFS 구성요소
| 구성요소 | 설명 |
| NameNode | - 파일시스템의 Metadata(디렉터리구조, Access 권한 등) 관리 서버 - 블록에 대한 배치정보를 관리, 특정 파일이 어떻게 블록으로 분할되어 어느 Data Node에 보관 유지되고 있는지를 관리 |
| DataNode | - 실제 데이터를 저장 유지하는 서버, Data Node간에는 데이터 복제를 통해 데이터의 신뢰성 유지함 |
| Secondary NameNode | - Name Node의 Metadata 로드가 실패 시 Backup Node로 사용 - Name Node에서 Secondary Name Node로 지속적 copy |
| Replication | - Datanode간 정보 복제 - 성능향상 및 장애시 지속적 서비스 제공 |
III. HDFS의 동작 절차
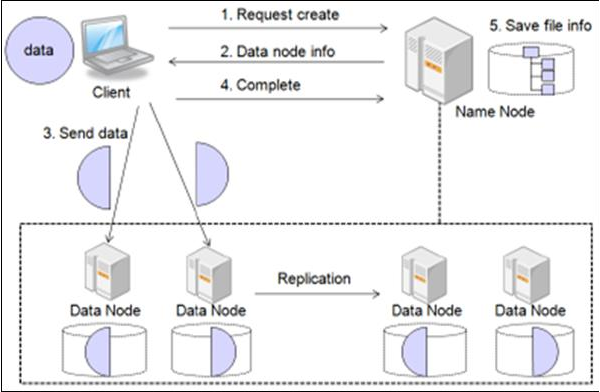
- HDFS는 마스터-슬레이브 구조로 동작하며, TCP/IP 프로토콜 이용하여 노드간 통신
- 대용량파일 원본을 저장 시 블록단위로 나누어 저장하며, 블록크기는 64/128MB 수준
- 노드의 실패에 대비해 데이터를 복제하여 저장하며, 동일 랙에 위치할 경우 노드간 대역폭이 높은 장점을 활용하는 Rack-aware 복제배치정책을 사용하고 있음
- (내부랙2개노드+다른랙1개노드)
가.

HDFS 데이터 분산, 복제 저장
나. HDFS 데이터 조회 절차
 |
다. HDFS 데이터 입력 절차

반응형
'정보관리기술사 > DB_데이터분석' 카테고리의 다른 글
| 샤딩(Sharding) / Shard (0) | 2023.08.27 |
|---|---|
| Hadoop 3.0 (0) | 2023.08.26 |
| Big Data 보안 (0) | 2023.08.24 |
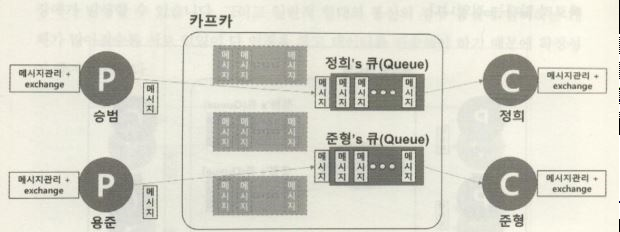
| 아파치 카프카(apache kafka) (1) | 2023.08.23 |
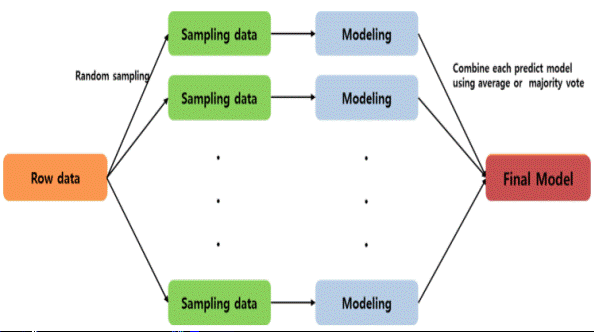
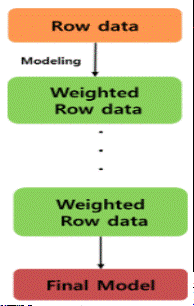
| 랜덤 포레스트(Random Forest) (0) | 2023.08.22 |