| 상 | 결함허용 컴퓨터(FTS) | HA, , Clustering, Database Recovery, 삼중구조(Triple Modular Redundency) |
| 토픽 이름 (상) | 결함허용 컴퓨터(FTS) |
| 분류 | CA > 고가용성 > 결함허용 컴퓨터(FTS) |
| 키워드(암기) | Graceful Degradation, 결함 감지/진단/통제/복구, H/W(TMR, Duplication, Stand by Sparing, Watchdog Timer, RAID), S/W(Check Point, Recovery Block, Conversation 등), DBMS(Rollback, Log File, Shadow Paging) |
| 암기법(해당경우) |
기출문제
| 번호 | 문제 | 회차 |
| 1 | 결합허용기법에는 H/W 결함허용기법, S/W 결함허용기법, 정보결함 | 53.관리.2 |
| 2 | RAID 시스템의 종류와 특징 및 FAULT TOLERANT SYSTEM과의 차이점 | 58.응용.2. |
| 3 | 10. 결함허용시스템(FTS, Fault Tolerant System)구현을 위한 TMR(Triple Modular Redundancy)에 대해 설명하시오. | 모의_16.01.응용.1 |
| 4 | 귀하는 사내 정보인프라 팀장으로서 강건한 시스템을 구축하기 위해 결함허용 시스템(FTS)의 도입을 검토중에 있다. 결함허용 시스템(FTS: Fault Tolerant System)의 기능과 기법을 설명하고 고가용성(HA)와 비교하시오. | 모의_10.10-1.공통.2 |
I. 어떤 상황에서도 안정화된 운영을 목적으로 결함 허용 시스템(Fault Tolerant System)의 개요
가. 결함 허용 시스템 정의
- 하드웨어 혹은 소프트웨어의 결함 또는 고장이 발생하여도 정상적 혹은 부분적으로 기능을 수행할 수 있는 시스템
나. 결함 허용 시스템 특징
| Graceful Degradation |
결함이나 고장이 발생하면 부분적인 기능을 사용할 수 없게되며, 계속적으로 부품의 결함이나 고장이 발생하면 점진적으로 사용 할 수 없는 기능 증가하며, 치명적 결함이나 고장 발생하면 시스템이 정지 |
II. 결함허용 시스템의 단계별 특성 및 관점별 기법
가. 단계별 특성
| 기능 | 내용 | 단계 |
| 결함감지 | Fault Detection, 시스템 내 결함 발생 및 내용 감지 | |
| 결함진단 | Fault Diagnosis, 결함의 원인/위치/파급효과 판단 | |
| 결함통제 | Fault Isolation, 결함으로 인한 오류파급 차단 | |
| 결함복구 | Fault Recovery & Reconfiguration 결함요소 제거, 시스템 재구성 |
나. FTS의 관점별 기법
| 관점 | 기법 | 설명 |
| Hardware | TMR (Triple Modular Redundancy) |
- 3개 이상의 프로세서가 같은 입력에 대하여 동일한 연산 수행 |
| Duplication with Comparison |
- 하드웨어 2개 중복 - 2개의 프로세서를 동기 상태에서 프로세스 수행 |
|
| Stand by Sparing | - 결함감지를 위한 여분의 하드웨어 | |
| Watchdog Timer | - 주기적 타이머 가동을 위한 초기화 | |
| RAID | - 디스크 미러링, 패리티 비트 | |
| Self-Purging Redundancy | - 출력결과가 틀린 하드웨어는 계산과정에서 배제 | |
| Software | Check point | - S/W 수행 중에 검사시점을 설정 - 오류발생이 발견되면 발생이전의 검사시점으로 되돌아가서 재수행 |
| Recovery Block | - 재 수행(Rollback & Retry)에 근거 - 단일 프로세서의 Rollback, Retry - 검사지점에서 오류가 발견되면 지정된 이전 검사점으로 되돌아가서 같은 기능을 가진 다른 S/W 모듈을 수행 |
|
| Conversation | - 재 수행(Rollback & Retry)에 근거한 Recovery의 확장형 - 복수의 프로세서 정보를 교환하는 프로세서들 간에 적용 가능한기법 |
|
| Distributed Recovery Block | - 분산 환경에서의 Rollback 기법 - Recovery Block 기법을 분산환경으로 확장 - H/W 결함과 S/W 결함을 동일한 방법으로 대처 |
|
| N self-checking programming | - 자가진단을 통한 컴포넌트의 결함 발견 - 2개 이상의 Self-Checking 컴포넌트가 수행되면서 하나는 주어진 기능을 수행하고 다른 컴포넌트는 대기상태 |
|
| N version programming | - H/W 결함허용 기법의 Triple Modular Redundancy와 유사 - N 개의 독립적인 S/W 모듈의 수행결과를 비교하여 다수의 수행결과를 채택 |
|
| DBMS | Rollback (Undo) | - 트랜잭션 ACID 보장 |
| Log File 활용 회복, Check Point, Shadow Paging |
- DB 회복 기법으로 활용 |
III. 결함허용 시스템 설계
가. 용어정리
| 용어 | 설명 |
| 결함 (Fault) | 시스템에 존재하는 결점 - 부정확한 요구사항 명세서, 부정확한 설계, 코딩 오류 |
| 오류 (Error) | 올바르지 않는 시스템의 동작 - 시간 조건 또는 경쟁 상태, 무한 반복, 프로토콜, 데이터 불일치, 잘못된 전송 또는 기록 |
| 장애 (Failure) | 시스템 명세서대로 동작하지 않는 시스템의 동작 - 멈추지 말아야 할 때 멈춤, 잘못된 결과 도출, 서비스 되지 않음, 사용자 조작에 무반응 |
| FTS 위한 Archi-tectural Patterns | 시스템 설계 초기, 내 결함 기능을 위한 아키텍쳐 설계 시, 발생하는 문제점에 대한 해결 방법이나 설계지침 |
| FTS 처리 위한 Core Patterns |
오류 감지 패턴 à 오류 복구 패턴 à 결함 치료 패턴 à 오류 완화 패턴 |
나. 시스템 설계
| 단계 | 패턴 | 설명 |
| 초기 단계 설계 패턴 |
완화 단위 만들기 (Units of Mitigation) |
-결함 허용 시스템의 기본단위. -기능 수행 자가체크 및 에러 복구 메커니즘 포함 |
| 검사하고 수정하기 (Correcting Audits) |
-H/W or S/W 에러 발생시 자동 수정 -체크섬, 직접적 비교 등 |
|
| 중복된 컴포넌트 및 기능 (Redundancy) |
-중복된 컴포넌트나 기능 제공하여 에러 처리 병렬적 수행 -시스템 이용성 증가 |
|
| 사람들의 간섭 최소화 (Minimize Human Intervention) |
-사람의 개입은 시스템 속도 저하시키거나 잘못된 오류 발생 -최대한 사람의 간섭을 배제 |
|
| 유지보수 인터페이스 만들기 (Maintenance Interface) |
-경험 있고 실력 있는 전문가들이 시스템을 모니터링 하거나 복구할 수 있도록 인터페이스 만들기 | |
| 책임자 두기 (Someone in Charge) |
-장애 발생시 시스템이 멈추지 않도록 에러를 감시하고 처리하는 책임자 두기 | |
| 단계적으로 확대 (Escalation) |
-에러 복구나 에러 완화에 실패하면 다음 단계의 더 강한 액션을 취함 | |
| 결함 감시자 두기 (Fault Observer) |
-모든 에러를 감시자에 레포트하면 결함 감시자는 관심을 가진 수신자에게 레포팅 | |
| 소프트웨어 업데이트 (S/W Update) |
-S/W Update 통해 지속적으로 결함을 제거하거나 기능을 향상시킴 | |
| 오류 감지 패턴 | 시스템 모니터 (System Monitor) |
-시스템이 제대로 수행되는지 확인 관찰하던 컴포넌트가 멈출경우 결함 감시자에게 레포트 하고 올바른 초기화 수행 |
| 심장박동 (Heart-beat) |
-관찰 되는 컴포넌트로부터 주기적으로 반응이 전달 됨 -이 방법 통해 시스템 모니터는 관찰 하는 컴포넌트 수행 감시 |
|
| 받았다고 알리기 (Acknowledgement) |
-두 개의 테스크 사이에서 상대방이 살아있고 제대로 기능 한다는 것을 알리는 방법 | |
| 실제 임계값 (Realistic Threshold) |
-ACK를 받기까지 기다린 시간을 실제 임계값과 비교하여 임계값 넘을 경우 결함관리자에 오류 레포트 | |
| 체크섬 (Checksum) |
-데이터 값이 정확하니 알아보는 방법 | |
| 오류 복구 패턴 | 재시작 (Restart) |
-오류 복구가 불가능 할 때 시스템을 재 시작함 |
| 재시도 횟수 제한 (Limit Retries) |
-똑같은 자극이 주어지면 똑같은 오류 발생 -똑같은 오류 발생마다 재시도 말고 오류 다룰 수 있는 전략 필요 |
|
| 데이터 리셋 (Data Reset) |
-수정할 수 없는 데이터가 있을 경우 초기값으로 리셋 | |
| 오류 완화 패턴 | 공평한 자원 할당 (Equitable Resource Allocation) |
-모든 비슷한 요청을 요청 풀(Pool)에 넣고 우선순위에 맞춰 공평하게 자원 할당 |
| 리소스 할당 위해 큐에 넣기 (Queue for Resources) |
-즉시 처리할 수 없는 요청은 큐에 넣어 순서에 맞춰 리소스를 할당 | |
| 새로운 일부터 하기 (Fresh Work Before State) |
-LIFO큐를 사용하여 새로운 요청을 가장 먼저 처리 | |
| 표시된 데이터 (Marked Data) |
-오류가 있는 데이터에 표시 하여 오류 처리 할 수 있도록 룰을 정의 | |
| 결함 치료 패턴 | 재통합 (Reintegration) |
-미리 정해진 절차에 따라 수정된 컴포넌트를 시스템에 재통합 수행 |
| 근본 원인 분석 (Root Cause Analysis) |
-오류나 결함의 근본원인 찾고 수정 |
----------- 추가 2018.05.14
모의_2017.12.응용.1
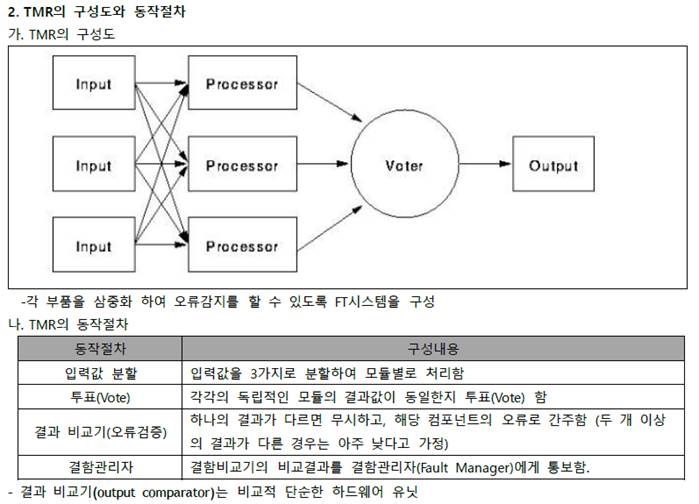
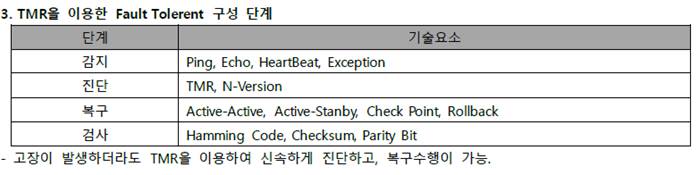
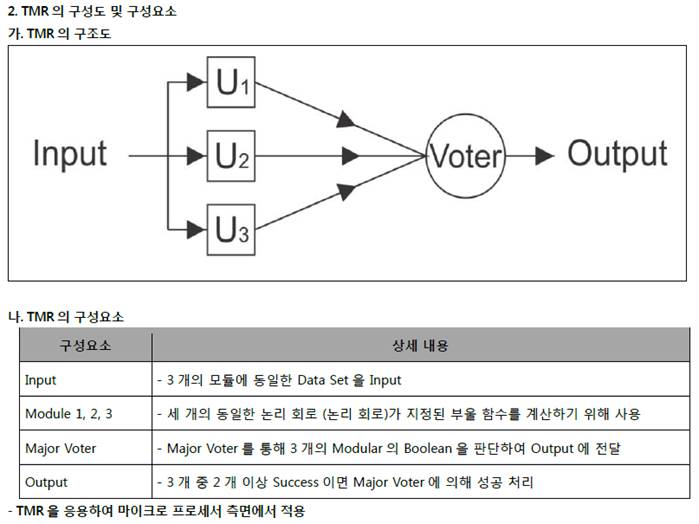
TMR(Triple Modular Redundancy)
- 세 개의 격리된 제어시스템과 하나의 통합된 진단기능을 사용하는 기술로 동일한 입력을 받는 3개의 동일한 컴포넌트를 중복 사용하여 결과를 비교 함.
- 세 개의 격리된 평행 제어 시스템과 하나의 시스템에 통합된 광대한 진단 기능을 사용
- 동일한 모듈 3 개 구성하여 Major Voter 를 통한 하나의 모듈에러, 나머지 2 개 Vote 에 의해 결정하는 결함허용시스템

-- 모의_2016.01.응용.1
반응형
'정보관리기술사 > CA_OS' 카테고리의 다른 글
| RAID (1) | 2023.11.21 |
|---|---|
| HA(High Availability) (1) | 2023.11.20 |
| Clustering (1) | 2023.11.18 |
| 관리정책 (0) | 2023.11.17 |
| Paging 기법(고정분할)/Segmentation(가변분할) (0) | 2023.11.16 |