| 상 | Data Mining | [정의] 대량의 데이터에 고급 통계 분석과 모델링 기법을 적용하여 데이터 간의 패턴과 관계를 도출, 의사결정에 활용할 수 있는 의미 있는 정보를 발견하는 과정 [데이터 마이닝 기법 종류] - 탐색적모델 : 연관성기법(association, 지지도/신뢰도/향상도), 연속성(Sequence), 군집화(Clustering) - 예측적모델 : 의사결정트리(Decision Tree), 신경망분석(NN), 분류화(Classification), 특성화(Characterization) [Data Mining 적용 기술] 연관성 규칙(Association), 연속성 규칙(Sequence), 분류, 데이터군집화, 특성화,신경망, 의사결정 [지지도, 신뢰도, 향상도 공식] 지지도 : P(A∩B) 신뢰도 : P(A|B) = P(A∩B) / P(A) 향상도 : P(A∩B) / P(A)P(B) |
Big Data 분석 의사결정트리 Smart Data |
AS 분데특신의 |
| 토픽 이름(상) | Data Mining |
| 분류 | IT 경영전략 > DW > Data Mining |
| 키워드(암기) | 연관성기법(지지도/신뢰도/리프트), 연속성, 분류, 군집화(Clustering), Machine Learning(기계학습 연계), 특성화, 의사결정트리 |
| 암기법(해당경우) | AS 분데특신의 |
기출문제
| 번호 | 문제 | 회차 |
| 1 | 특정 개인의 프라이버시(privacy)를 보호하면서도 그 개인의 정보를 사용하기 위해 설계된 방법의 하나인 PPDM(Privacy Preserving Data Mining)을 정의하고, 그 기법에 대하여 설명하시오. | 113.정보관리.3 |
| 2 | CRISP-DM(Cross Industry Standard Process for Data Mining) | 111.정보관리.1 |
| 3 | 8. 데이터 마이닝(Data mining)의 기법 5가지에 대하여 설명하시오. | 99.정보관리.1.8 |
| 4 | 12. 일반적인 데이터마이닝(Data Mining)의 수행단계를 설명하시오. | 98.정보관리.1.12 |
| 5 | 3. 데이터 마이닝(Data mining)의 과정, 기법 및 활용사례에 대하여 설명하시오. | 96.정보관리.4.3 |
| 6 | 4.BI에서 Data mining과 Text Mining을 비교 설명하시오 | 95.응용.4.4 |
I. 합리적 의사결정을 위한 가치정보 추출, Data Mining의 개요
가. Data Mining의 정의
- 대량의 데이터에 고급 통계 분석과 모델링 기법을 적용하여 데이터 간의 패턴과 관계를 도출, 의사결정에 활용할 수 있는 의미 있는 정보를 발견하는 과정
II. Data Mining 모델링 유형 및 Data Mining 적용 기술
가. Data Mining 모델링 유형

나 Data Mining 적용 기술(AS 분데특신의)
| 기술(기법) | 설명 |
| 연관성 규칙 (Association) |
- 여러 개의 트랜잭션들 중에서 동시에 발생하는 트랜잭션의 연관 관계를 발견 [사례] - 넥타이를 구매하는 고객이 셔츠를 50%이상 구매하고, 정장과 벨트를 구매하는 고객은 코트를 구매할 확률이 40% 이상 - 교차판매, 묶음판매, 상품의 진열, 쿠폰 배부 등의 분야에서 활용 |
| 연속성 규칙 (Sequence) |
- 개인별 트랜잭션 이력 데이터를 시계열적으로 분석하여 트랜잭션의 향후 발생 가능성을 예측하는 것 [사례] - A품목을 구입한 회원이 향후 H품목을 구입할 가능성은 75%이다. - 5번 회원에게 H품목을 추천하여 마케팅의 정확성을 높임 |
| 분류 (Classification) |
- 이미 알려진 특정 그룹의 특징을 부여하고 정의된 분류에 맞게 구분 [사례] - 신용카드 신규 가입자를 낮음/중간/높음 신용 위험 집단으로 구분 - 경쟁자에게 이탈한 고객 |
| (데이터)군집화 (Clustering) | - 상호간에 유사한 특성을 갖는 데이터들을 집단화 하는 과정 - 미리 정의한 특성에 대한 정보를 가지지 않는다는 점에서 ‘분류’와 차이 - K-means 알고리즘 [사례] - A~D의 데이터를 집단화하는 과정에서 고객 군집 별 특성을 파악함 - A 군집은 소득이 300만원 이상이고, 자녀가 2-3명이고 연령이 30대 군집 - B군집은 교육 수준이 높으며, 자녀는 모두 출가했고, 연평균 구매액이 200~300만원 정도 |
| 특성화 (Characterization) |
- 데이터 집합의 일반적인 특성을 분석하는 것으로 데이터의 요약 과정을 통하여 특성 규칙을 발견하는 것 |
| 신경망 분석 (Neural Network) |
뇌를 모방, 학습을 통한 예측(입력-은닉-출력) |
| 의사결정트리 | 과거에 수집된 데이터들을 분석하여 이들 사이에 존재하는 패턴을 분류, 해당 분류의 값을 예측하는데 사용 |
IV. 일반적인 Data Mining의 수행단계
가. Data Mining의 수행단계 개념도
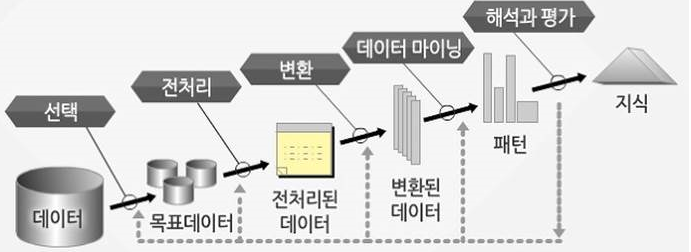
나. Data Mining 상세 수행단계

IV. Data Mining과 OLAP 비교
가. Data Mining과 OLAP의 개념도

- 분석 대상 데이터를 수집하여 가공 후 DW에 적제 시켜 분석 도구를 통해 사용자에게 제공
- OLAP(Online Analytical Processing)은 정보사용자가 직접 접근하여 다차원 질의를 통해 대화식으로 정보를 탐색하고 분석하는 프로세스
나. Data Mining과 OLAP의 비교표
| 구분 | Data Mining | OLAP |
| 개념 | -컴퓨터 가설을 세우고 검증하는 기법 -발견형(Discovery-Driven)기법 -패턴 주론 |
-분석과정에서 사용자들의 사전지식 검증 -검증형(Verification-Driven)기법 - 특정 사실에 대한 가/부 판단 |
| 판정기준 | 가설 | 입증 |
| 주체 | 컴퓨터 | 사용자 |
| 요구사항 | 자동 추출 | 사용자의 방대한 지식 |
| 특징 | 진보적인 방법 | 고전적인 방식 |
| 단점 | 분석기법 이해 필요 | 사용자가 모든 질문 생각 |
| 차이점 | 그 뒤에 숨겨진 일반적인 경향 정보 | 특정 물음에 대한 정보 제공 |
| 공통점 | -데이터 사이의 새로운 관계를 찾아내는 과정 -Data Warehouse의 활용을 높이는 방안 |
“끝”
[참고] Apriori 알고리즘 풀이 예시
I. 연관 규칙의 3가지 척도 및 사례
- 연관 규칙을 찾아주는 알고리즘 중에서 가장 먼저 개발
가. 연관 규칙의 3가지 척도 (A à B)
| 구분 | 기술(기법) | 설명 |
| 지지도 (Support) |
- A, B를 동시에 구매하는 비율 - 지지도 = 교사건 = 교집합 |
Pr(A∩B) / Pr(*) 두 항목을 동시에 구매한 거래 수 / 전체 거래 수 |
| 신뢰도 (Confidence) |
- 항목 A의 거래 중 항목 B가 포함된 거래의 비율(조건부 확률) | Pr(A∩B) / Pr(A) 두 항목을 동시에 구매한 거래 수 / A항목의 거래 수 |
| 향상도 (Lift) |
- 항목 B가 항목 A와 동시에 구매되는 경우(즉, 신뢰도)와 B 자체만 구매되는 경우의 비율 (적용) - 독립관계 (향상도=1) - 양의 상관관계 (향상도 > 1) - 음의 상관관계 (향상도 < 1) |
{ Pr(A∩B) / ( Pr(A) * Pr(B) ) } * Pr(*) {두 항목을 동시에 구매한 거래 수 / (A항목의 거래 수 * B항목의 거래 수) } * 전체 거래 수 |
나. 연관 규칙 사례 (모니터 à 키보드)
| 예시 | 구분 | 설명 |
| 지지도 (Support) |
Pr(모니터∩키보드) / Pr(*) à 2 / 4 à 0.5 à 50% | |
| 신뢰도 (Confidence) |
Pr(모니터∩키보드) / Pr(모니터) à 2 / 3 à 0.667 à 66.7% | |
| 향상도 (Lift) |
{ Pr(모니터∩키보드) / ( Pr(모니터) * Pr(키보드) ) } * Pr(*) à {2 / (3 * 3)} * 4 à 0.889 à 음의 상관관계 |
반응형
'정보관리기술사 > IT경영' 카테고리의 다른 글
| DRP (0) | 2024.01.14 |
|---|---|
| BIA (1) | 2024.01.13 |
| 공유경제(sharing economy) (2) | 2024.01.11 |
| 섭테크 (0) | 2024.01.10 |
| 에이블테크(AbleTech) (0) | 2024.01.09 |