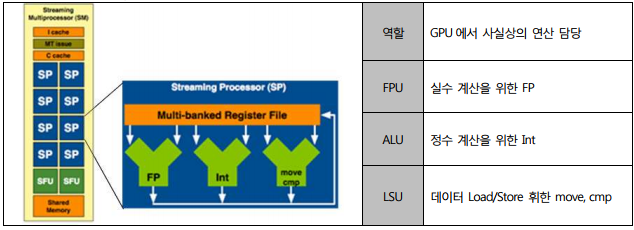
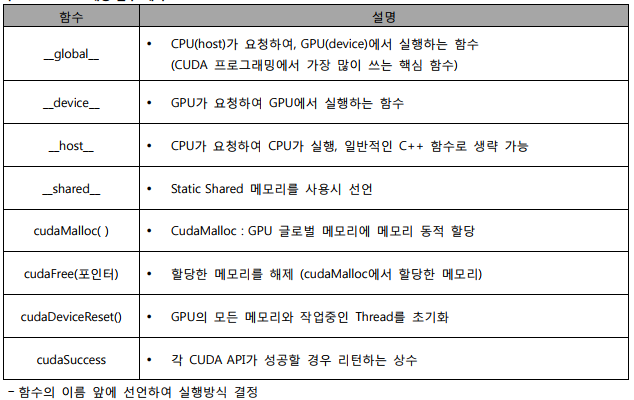
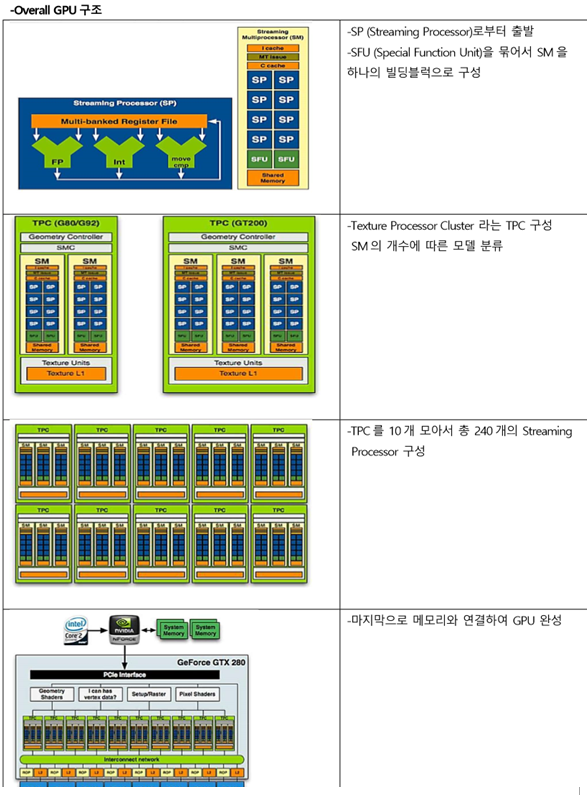
| 상 | MESI | M(수정),E(배타,유일,메인메모리동일),S(공유,2이상캐시),I(무효,다른캐시수정) Read miss(I상태에서변경),Read Hit(읽기적중), Write Miss(Read with intend to modify, I->M, E->M), Write Hit |
| 토픽 이름 (중) | MESI |
| 분류 | CA > Cache Memory> MESI |
| 키워드(암기) | Snoopy, 수정, 배타, 공유, 무효, Write-through, Write-back |
| 암기법(해당경우) |
기출문제
| 번호 | 문제 | 회차 |
| 1 | 5. 캐시 일관성 유지를 위한 MESI 프로토콜 | 합숙_2020.01공통Day-5 |
| 2 | 4. Cache Memory에 대하여 다음에 답하시오 가. Cache Coherence의 개념 나. Write through와 Write Back 비교 설명 다. 캐시 일관성 유지를 위한 MESI 프로토콜 |
모의_2019.03.관리.3 |
| 3 | 1. 캐쉬 일관성 유지 프로토콜 중 하나인 MESI 프로토콜에 대해 설명하고, 2 개의 프로세서가 1 개의 공유메모리를 공유하는 시스템에서 캐쉬 일관성 프로토콜로 MESI 프로토콜을 사용할 경우, 아래 ①, ②, ③으로 표기된 상태전이가 각각 어떤 상황에서 발생하는지 프로세서, 캐쉬, 주기억장치를 도식화하여 설명하시오. | 모의_16.11_응용_3 |
| 4 | 5. Cache 의 일관성(Coherency)을 유지하는 MESI 프로토콜에 대해서 설명하시오. | 모의_15.1_관리_1 |
I. Cache 일관성 유지 프로토콜, MESI 프로토콜의 개요
가. MESI 프로토콜의 정의
- 멀티 프로세서 시스템에서 Cache 일관성 유지 위해 메모리가 가질 수 있는 네 가지의 상태 정의한 Cache 일관성 유지 프로토콜
나. MESI 프로토콜의 특징
- 프로세서가 Cache 데이터 변경해도 주기억장치의 내용은 갱신되지 않음.
- 변경된 Cache의 스누피 제어기가 변경 사실을 다른 스누피 제어기들에게 통보함.
II. MESI 프로토콜의 상태 전이도 및 설명
가. MESI 프로토콜의 상태 전이도
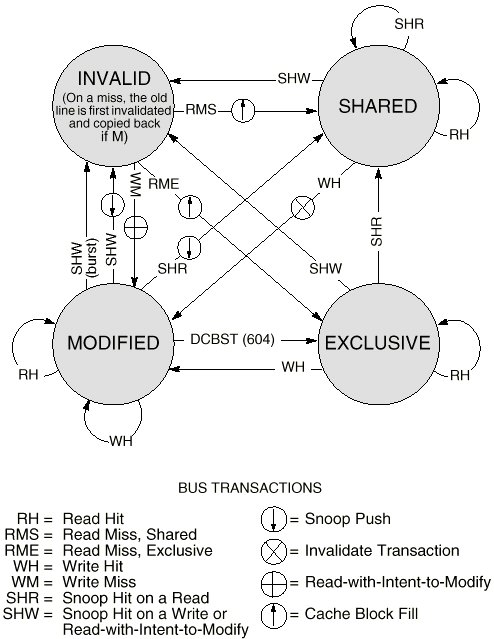 |
 |
- 실선은 프로세스 동작에 의한 전이, 점선은 다른 캐시 변화에 따른 전이
나. MESI 프로토콜 전이 상태와 전이 동작 설명
- 스누핑(Snooping): 주소 버스를 항상 감시하여 캐시 상 메모리에 대한 접근 여부 감시하는 구조. 다른 캐시에서 쓰기 발생 시 캐시 컨트롤러에 의해 자신의 캐시에 있는 복사본을 무효화시킴.
- Cache 일관성 유지 위한 MESI 프로토콜
| Cache block 상태 | 의미 |
| 수정 (Modified) | 캐시 내의 라인이 수정되었으며 (주기억장치와 상이), 그 라인은 이 캐시에만 있다. |
| 배타 (Exclusive) | 캐시 내의 라인은 주기억장치에 있는 것과 동일하며, 다른 캐시에는 존재하지 않는다. |
| 공유 (Shared) | 캐시 내의 라인은 주기억장치에 있는 것과 동일하며, 다른 캐시에도 있을 수 있다. |
| 무효 (Invalid) | 캐시 내의 라인은 유효한 데이터를 포함하고 있지 않다. |
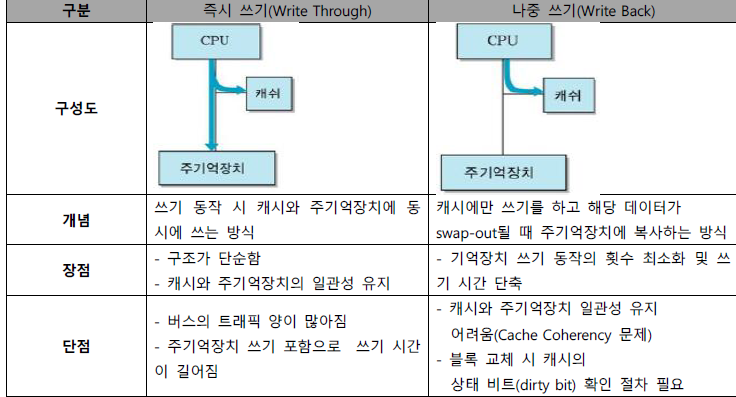
III. Write-through, Write-back 일관성 유지 프로토콜의 비교
| Write-through 일관성 유지 프로토콜 | Write-back 일관성 유지 프로토콜 |
| - 프로세서가 캐시 데이터 수정 시 동시에 주기억 장치도 갱신 - 주기억장치에 대한 쓰기 동작의 주소가 자신의 캐시에 있는지 검사 - 검사해서 있으면 해당 블록 무효화 |
- 프로세서가 캐시 데이터를 수정해도 주기억장치 내용은 갱신되지 않음. - 변경된 캐시의 스누피 제어기가 변경 사실을 다른 스누피 제어기들에게 통보 - 무효화 신호, 무효화 사이클 사용 |
“끝”
반응형
'정보관리기술사 > CA_OS' 카테고리의 다른 글
| 주소 변환 기법 (0) | 2023.11.15 |
|---|---|
| 가상 메모리 (0) | 2023.11.14 |
| 집합연관사상 (1) | 2023.11.12 |
| 연관사상(Associative Mapping) (0) | 2023.11.11 |
| 직접사상(Direct Mapping) (0) | 2023.11.10 |