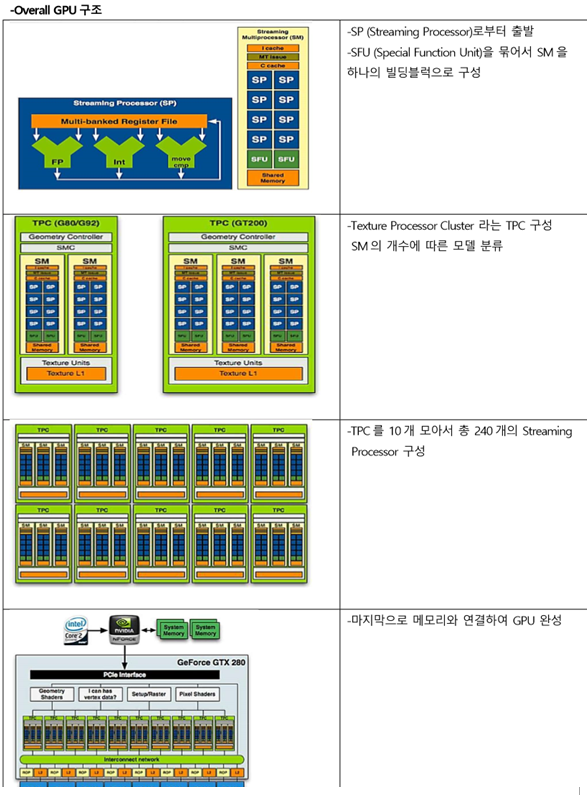
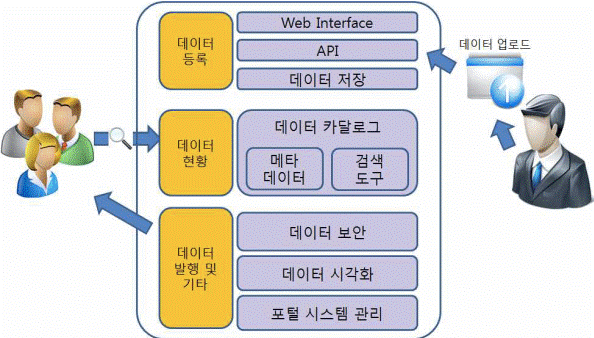
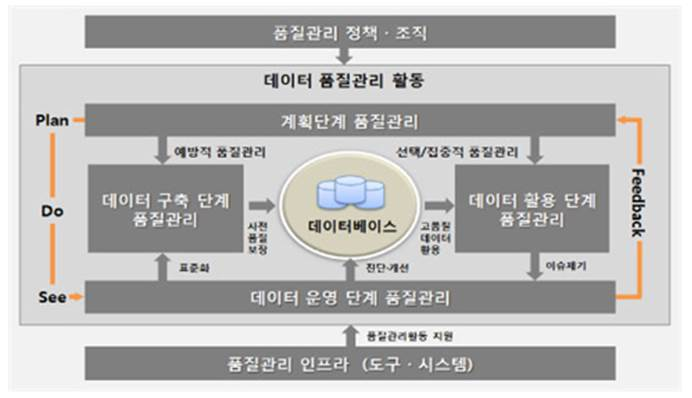
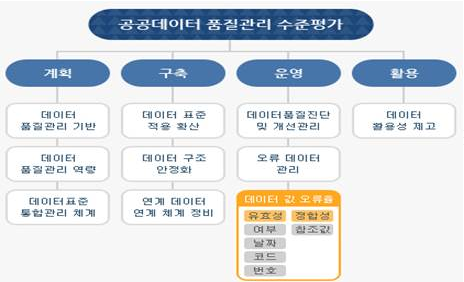
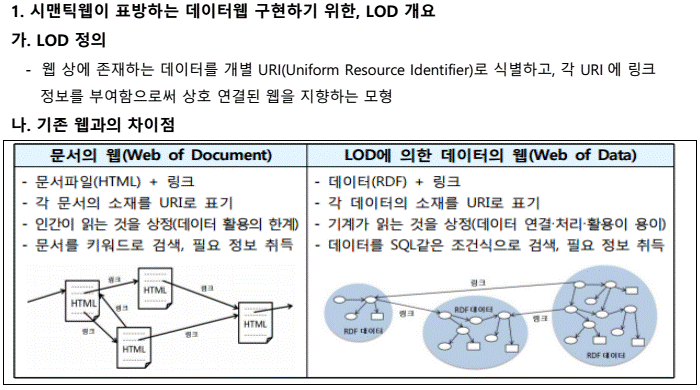
| 중 | 매니코어 프로세서 (many core CPU(Central Processing Unit)) |
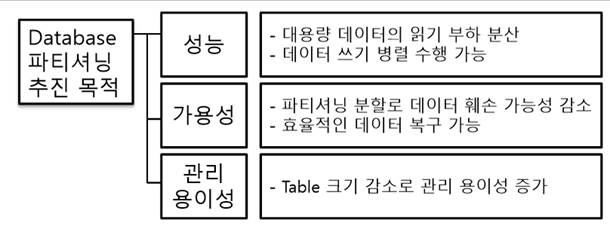
[정의] CPU에 수십개에서 수백개의 코어를 집적하여 극한의 병렬화 된 프로그램 실행을 목적으로 하는 프로세서 [기술요소] 프로세싱 ( 병렬 컴퓨팅, 캐시 일관성, 하드웨어 추상화 ) 메모리 ( Messaing Passing, Scratchpad memory, 메모리 주소 분할 ) |
123회 컴시응 1교시 기출 |
| 토픽 이름 (상) | 매니코어 프로세서(many core CPU(Central Processing Unit)) |
| 분류 | CA > 컴퓨터 구조 > 매니코어 프로세서 |
| 키워드(암기) | NUCA, NoC, Nano 집적기술, 3D die Stacking, DVFS |
| 암기법(해당경우) |
기출문제
| 번호 | 문제 | 회차 |
| 1 | 5. 매니코어 프로세서(many core CPU(Central Processing Unit)) | 123.컴시응.1 |
I. 극한의 병렬 처리 프로세서, 매니코어 프로세스(Many core CPU)의 개요
| 정의 | CPU에 수십개에서 수백개의 코어를 집적하여 극한의 병렬화 된 프로그램 실행을 목적으로 하는 프로세서 |
| 특징 | - 병렬처리, 다수 코어 집적, 캐시 일관성, 메모리 분할 |
- 병렬처리에 최적화 되어 있어 병렬 프로그램 이외엔 성능이 하락
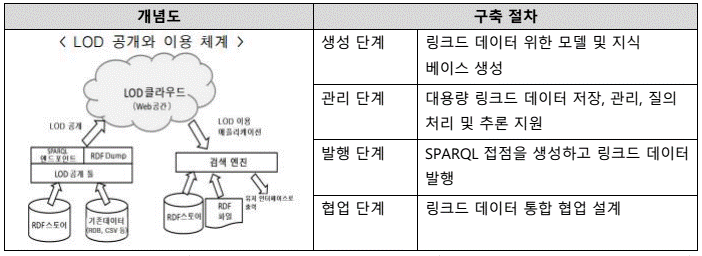
II. 매니코어 프로세서의 개념도 및 기술요소 설명
가. 매니코어 프로세서의 개념도
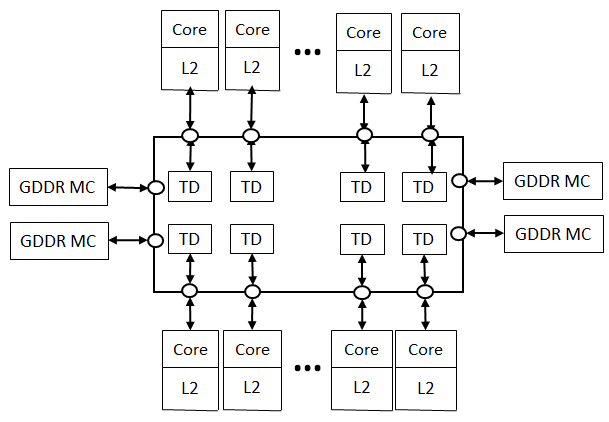 |
- 다수의 Core를 하나의 CPU에 집적해 병렬처리를 극대화 함
나. 매니코어 프로세서의 기술요소
| 구분 | 핵심 기술 | 설명 |
| 하드웨어 측면 |
NUCA(Non-Uniform Cache Architecture) | - 각 코어블록과 지리적 근접 L2 Cache Bank에 접근하도록 하여 Bandwidth를 향상 |
| 3D die Stacking | - SOC die 내부의 여러 지점에 Memory die와 연결되는 via를 제공하여 대여폭을 향상시키고 훨씬 많은 수의 연결을 지원 | |
| NoC(Network on Chip) | - 프로세스 내 인터커넥션을 위한 라우터를 통한 고속의 네트워크를 구현 | |
| DVFS(Dynamic Voltage Frequency Scaling) | - 프로세서의 전력 효율을 향상, 처리량 대비 가변적 전압과 주파수 적용 - 처리량이 많을 시는 전압과 주파수를 높이고, 처리량이 적을 시는 전압과 주파수를 낮추어 에너지 효율성 향상 |
|
| Internal Memory Controller | - 프로세서 내부에 메모리 컨트롤러를 내장하여 매니코어의 메모리 접근성을 향상 | |
| Nano 집적 기술 | - 단일 프로세서 칩에 집적하기 위한 50nm 이하의 소자를 집적하는 기술, 현재 10nm 이하 소자 집적으로 기술 발전중 | |
| 소프트웨어 측면 |
Massage Passing | - 병렬 처리에서 정보 교환 시에 필요한 기본 기능들과 문법, 프로그래밍 API에 대한 표준 기술 |
| Transaction Memory | - 병렬 컴퓨팅에서 공유 메모리 접근을 제어하기 위한 동시성 제어 기법 | |
| SPMT(Serial Port Memory Technology) | - 수행 확률이 높은 부분을 다른 core를 통해 미리 수행하여 전체 성능을 향상시키는 기법 | |
| Token Based Coherence Protocol | - cache coherence 위한 토큰 기반의 프로토콜 | |
| SW 지원 플랫폼 | - OpenMP, OpenCL, CUDA등 병렬 프로그램 지원 플랫폼 |
- 병렬 컴퓨팅에 최적화 되 다수의 코어를 사용해 연산처리에 매니코어 프로세서 활용 가능
III. 매니코어 프로세서와 멀티코어 프로세서의 비교
| 비교 | 매니코어 프로세서 | 멀티코어 프로세서 |
| 개념 | - CPU에 다수의 코어를 집적 | - 다이에 다수의 CPU를 집적 |
| 코어 | - 동일한 코어 집적 | - 다양한 기능의 코어를 집적 |
| 예시 | - Intel Core i5 | - Intel Xeon |
“끝”
반응형
'정보관리기술사 > CA_OS' 카테고리의 다른 글
| 집합연관사상 (1) | 2023.11.12 |
|---|---|
| 연관사상(Associative Mapping) (0) | 2023.11.11 |
| 직접사상(Direct Mapping) (0) | 2023.11.10 |
| Cache 일관성 유지방법 (0) | 2023.11.09 |
| GPGPU - CUDA (0) | 2023.11.07 |